
PaCoRe
Collection
Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
•
3 items
•
Updated
•
4
conversation
list | responses
list | ground_truth
dict |
|---|---|---|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["Okay, let's see. I need to solve this pouring problem. So the task is to simulate pouring operatio(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/11020","value":{"prelude":null,"speed_tests":[{"answer_file_cont(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nGiven (...TRUNCATED)
| ["We are given:\n cellPrice: list of n integers, cellPrice[i] = cost to enter i (if -1, blocked)\n (...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/9794","value":{"prelude":null,"speed_tests":[{"answer_file_conte(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["We are given a string S and two integers: good and bad.\n We traverse each character in S from lef(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/13119","value":{"prelude":null,"speed_tests":[{"answer_file_cont(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nWe def(...TRUNCATED)
| ["We are guaranteed that the string has at least 2 characters.\n The problem: We want to transform S(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/16910","value":{"prelude":null,"speed_tests":[{"answer_file_cont(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["Okay, let's try to figure out how to solve this problem. So, the problem is about finding the maxi(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/1140","value":{"prelude":null,"speed_tests":[{"answer_file_conte(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["We are given that numHoles is at most 10, so we can try to generate all possible subsets of positi(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/8819","value":{"prelude":null,"speed_tests":[{"answer_file_conte(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["We are given a string S of 'B' and 'W'. We want to rearrange it so all 'W' are before all 'B'. We (...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/11418","value":{"prelude":null,"speed_tests":[{"answer_file_cont(...TRUNCATED)
|
[{"content":"Finish the given class or function, according to the problem statement below.\n\nYou ar(...TRUNCATED)
| ["We are given a list X of integers. We perform the process: for an initial value, we go through X a(...TRUNCATED)
| {"tag":"topcoder_sted_topcoder_pyst/13088","value":{"prelude":null,"speed_tests":[{"answer_file_cont(...TRUNCATED)
|
[{"content":"Write a python program to solve the problem below, read input from stdin and print outp(...TRUNCATED)
| [" Okay, the problem is about assigning non-negative integers to the edges of a tree such that for e(...TRUNCATED)
| {"tag":"deepcoder/primeintellect/3013","value":{"prelude":"from string import *\nfrom re import *\nf(...TRUNCATED)
|
[{"content":"Write a python function `mystery` to solve the problem below.\n\nNo Story\n\nNo Descrip(...TRUNCATED)
| ["We are given a number `n` and we need to return the result of `mystery(n)`.\n We have 35 problems (...TRUNCATED)
| {"tag":"deepcoder/primeintellect/12879","value":{"prelude":"from string import *\nfrom re import *\n(...TRUNCATED)
|
We introduce PaCoRe (Parallel Coordinated Reasoning), a framework that shifts the driver of inference from sequential depth to coordinated parallel breadth, breaking the model context limitation and massively scaling test time compute:
Trained via large-scale, outcome-based reinforcement learning, PaCoRe masters the Reasoning Synthesis capabilities required to reconcile diverse parallel insights.
The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5’s 93.2% by scaling effective TTC to roughly two million tokens.
We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work!
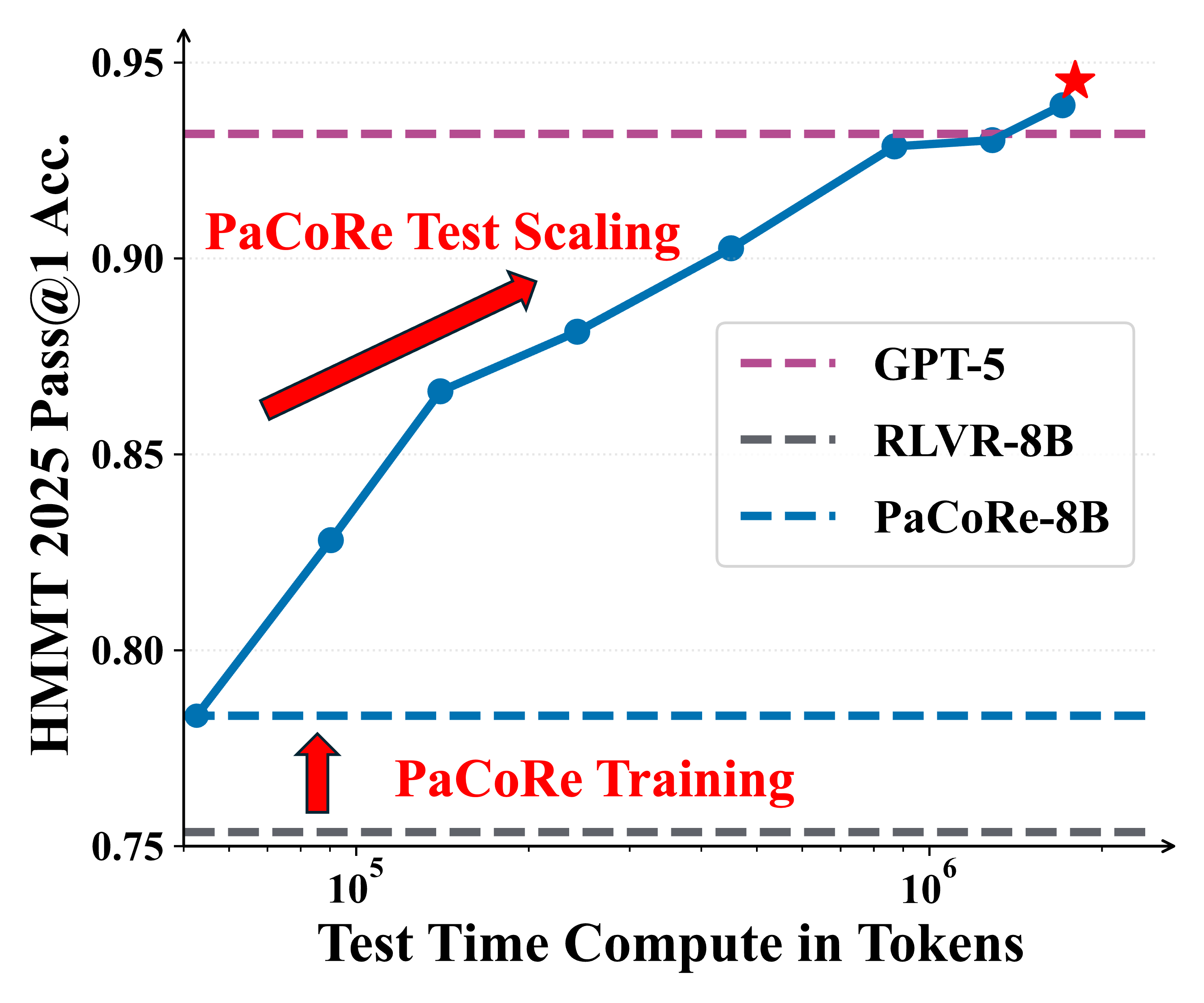
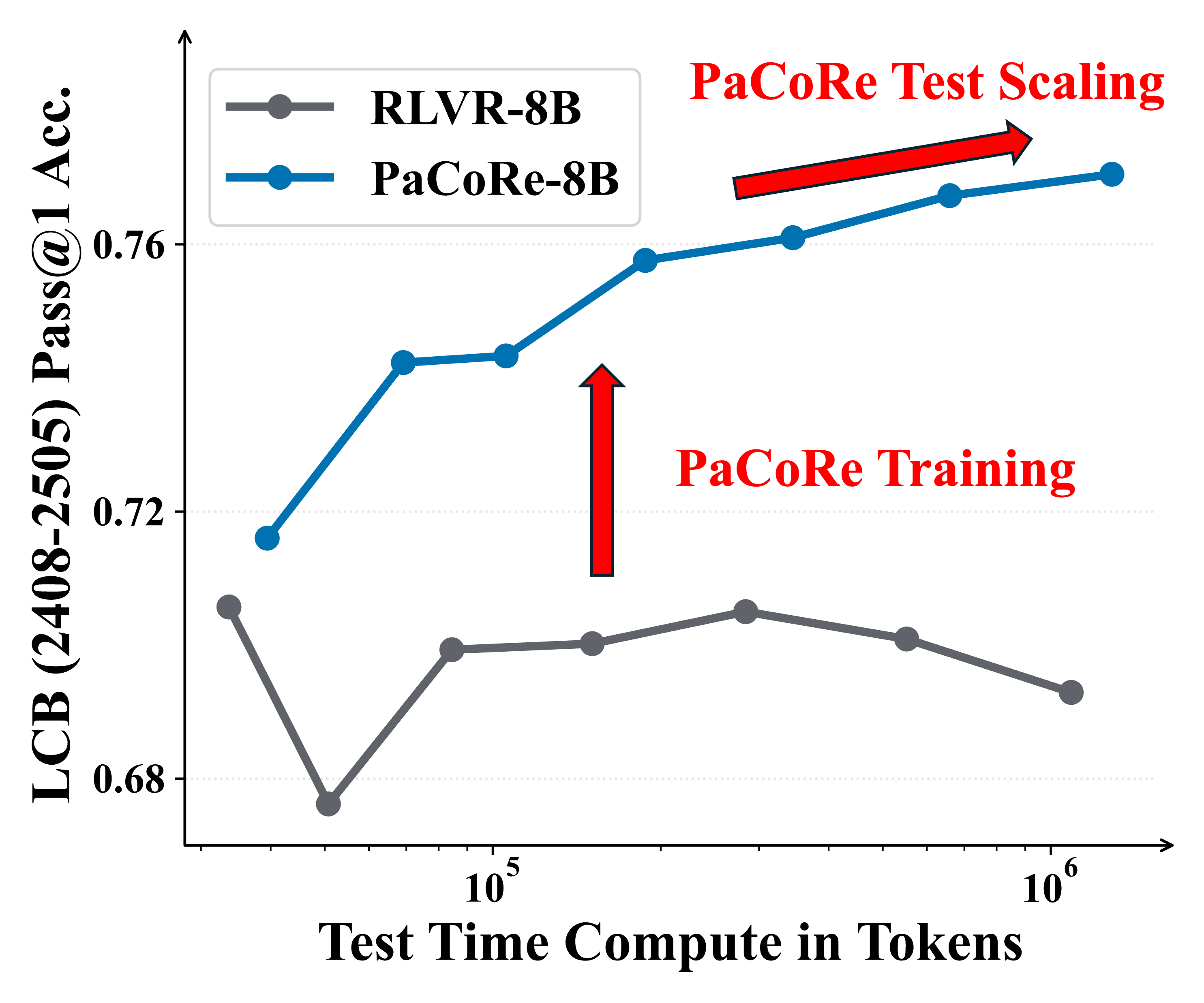
Figure 1 | Parallel Coordinated Reasoning (PaCoRe) performance. Left: On HMMT 2025, PaCoRe-8B demonstrates remarkable test-time scaling, yielding steady gains and ultimately surpassing GPT-5. Right: On LiveCodeBench, the RLVR-8B model fails to leverage increased test-time compute, while PaCoRe-8B model effectively unlocks substantial gains as the test-time compute increases.


Figure 2 | PaCoRe Training dynamics. Left panels: The Training Reward and Response Length steadily increase, demonstrating the training stability and effectiveness. Right panels: Evaluation on HMMT 2025 and LiveCodeBench (2408-2505). Performance is reported using single round coordinated reasoning in PaCoRe inference setting with $\vec{K} = [16]$.
[2025/12/09] We are excited to release the PaCoRe-8B ecosystem:
opensource_math, public_mathcontest, synthetic_math and code: | HMMT 2025 | LiveCodeBench | HLEtext | MultiChallenge | |
|---|---|---|---|---|
| GPT-5 | 93.2 (16k) | 83.5 (13k) | 26.0 (14k) | 71.1 (5.0k) |
| Qwen3-235B-Thinking | 82.3 (32k) | 74.5 (21k) | 18.2 (23k) | 60.3 (1.6k) |
| GLM-4.6 | 88.7 (25k) | 79.5 (19k) | 17.2 (21k) | 54.9 (2.2k) |
| DeepSeek-v3.1-Terminus | 86.1 (20k) | 74.9 (11k) | 19.3 (18k) | 54.4 (1.1k) |
| Kimi-K2-Thinking | 86.5 (33k) | 79.2 (25k) | 23.9 (29k) | 66.4 (1.7k) |
| RLVR-8B | 75.4 (48k) | 70.6 (34k) | 9.3 (35k) | 33.3 (1.7k) |
| PaCoRe-8B (low) | 88.2 (243k) | 75.8 (188k) | 13.0 (196k) | 41.8 (13k) |
| PaCoRe-8B (medium) | 92.9 (869k) | 76.7 (659k) | 14.6 (694k) | 45.7 (45k) |
| PaCoRe-8B (high) | 94.5 (1796k) | 78.2 (1391k) | 16.2 (1451k) | 47.0 (95k) |
Table 1 | For each benchmark, we report accuracy together with total TTC (in thousands). For Low, Medium, and High, we apply the inference trajectory configuration as $\vec{K}=[4]$, $[16]$, and $[32, 4]$ separately.
The data is provided as a list[dict], where each entry represents a training instance:
conversation: The original problem/prompt messages.responses: A list of cached generated responses (trajectories). These serve as the input messages ($M$) used during PaCoRe training.ground_truth: The verifiable answer used for correctness evaluation.You can directly use vllm serve to serve the model! More inference details of PaCoRe will be handled in Inference Pipeline.

Figure 3 | Inference pipeline of PaCoRe. Each round launches broad parallel exploration, compacts the resulting trajectories into compacted messages, and feeds these messages together with the question forward to coordinate the next round. Repeating this process $\hat{R}$ times yields multi-million-token effective TTC while respecting fixed context limits, with the final compacted message serving as the system’s answer.
Inference code coming soon!
We are just scratching the surface of parallel coordinated reasoning. Our roadmap includes:
We are currently seeking self-motivated engineers and reseachers. If you are interested in our project and would like to contribute to the reasoner scale-up all the way to AGI, please feel free to reach out to us at [email protected]
@misc{pacore2025,
title={PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning},
author={Jingcheng Hu and Yinmin Zhang and Shijie Shang and Xiaobo Yang and Yue Peng and Zhewei Huang and Hebin Zhou and Xin Wu and Jie Cheng and Fanqi Wan and Xiangwen Kong and Chengyuan Yao and Ailin Huang and Hongyu Zhou and Qi Han and Zheng Ge and Daxin Jiang and Xiangyu Zhang and Heung-Yeung Shum},
year={2025},
url={[https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf](https://github.com/stepfun-ai/PaCoRe/blob/main/pacore_report.pdf)},
}