Datasets:


Upload 5 files
Browse files- .gitattributes +1 -0
- DataPreparation.ipynb +64 -0
- README.md +127 -1
- example1.png +3 -0
- example2.png +3 -0
- table_extract.csv +3 -0
.gitattributes
CHANGED
|
@@ -53,3 +53,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 53 |
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 54 |
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
*.webp filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 53 |
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 54 |
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
table_extract.csv filter=lfs diff=lfs merge=lfs -text
|
DataPreparation.ipynb
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 3,
|
| 6 |
+
"metadata": {
|
| 7 |
+
"id": "SFEUqifXS0At"
|
| 8 |
+
},
|
| 9 |
+
"outputs": [
|
| 10 |
+
{
|
| 11 |
+
"name": "stderr",
|
| 12 |
+
"output_type": "stream",
|
| 13 |
+
"text": [
|
| 14 |
+
"Processing CSV files: 100%|██████████| 16573/16573 [01:14<00:00, 222.34it/s]\n"
|
| 15 |
+
]
|
| 16 |
+
}
|
| 17 |
+
],
|
| 18 |
+
"source": [
|
| 19 |
+
"import os\n",
|
| 20 |
+
"import pandas as pd\n",
|
| 21 |
+
"from tqdm import tqdm\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"# Create an empty DataFrame\n",
|
| 24 |
+
"df = pd.DataFrame()\n",
|
| 25 |
+
"df['context'] = None\n",
|
| 26 |
+
"df['answer'] = None\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"# Read all CSV files from the folder 'all_csv'\n",
|
| 29 |
+
"folder_path = 'all_csv' # Path to the folder containing CSV files\n",
|
| 30 |
+
"paths = [os.path.join(folder_path, filename) for filename in os.listdir(folder_path) if filename.endswith('.csv')]\n",
|
| 31 |
+
"for i, path in enumerate(tqdm(paths, desc=\"Processing CSV files\")):\n",
|
| 32 |
+
" data = pd.read_csv(path, sep='#')\n",
|
| 33 |
+
" df.loc[i, 'context'] = data.to_string()\n",
|
| 34 |
+
" df.loc[i, 'answer'] = data.to_json(force_ascii=False)\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"# Write the DataFrame to a CSV file\n",
|
| 37 |
+
"df.to_csv('table_extract.csv', index=False)"
|
| 38 |
+
]
|
| 39 |
+
}
|
| 40 |
+
],
|
| 41 |
+
"metadata": {
|
| 42 |
+
"colab": {
|
| 43 |
+
"provenance": []
|
| 44 |
+
},
|
| 45 |
+
"kernelspec": {
|
| 46 |
+
"display_name": "Python 3",
|
| 47 |
+
"name": "python3"
|
| 48 |
+
},
|
| 49 |
+
"language_info": {
|
| 50 |
+
"codemirror_mode": {
|
| 51 |
+
"name": "ipython",
|
| 52 |
+
"version": 3
|
| 53 |
+
},
|
| 54 |
+
"file_extension": ".py",
|
| 55 |
+
"mimetype": "text/x-python",
|
| 56 |
+
"name": "python",
|
| 57 |
+
"nbconvert_exporter": "python",
|
| 58 |
+
"pygments_lexer": "ipython3",
|
| 59 |
+
"version": "3.10.4"
|
| 60 |
+
}
|
| 61 |
+
},
|
| 62 |
+
"nbformat": 4,
|
| 63 |
+
"nbformat_minor": 0
|
| 64 |
+
}
|
README.md
CHANGED
|
@@ -1,3 +1,129 @@
|
|
| 1 |
-
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
license: apache-2.0
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
configs:
|
| 5 |
+
- config_name: default
|
| 6 |
+
data_files:
|
| 7 |
+
- split: train
|
| 8 |
+
path: table_extract.csv
|
| 9 |
+
tags:
|
| 10 |
+
- TABLES
|
| 11 |
---
|
| 12 |
+
|
| 13 |
+
# Table Extract Dataset
|
| 14 |
+
This dataset is designed to evaluate the ability of large language models (LLMs) to extract tables from text. It provides a collection of text snippets containing tables and their corresponding structured representations in JSON format.
|
| 15 |
+
## Source
|
| 16 |
+
The dataset is based on the [Table Fact Dataset](https://github.com/wenhuchen/Table-Fact-Checking/tree/master?tab=readme-ov-file), also known as TabFact, which contains 16,573 tables extracted from Wikipedia.
|
| 17 |
+
|
| 18 |
+
## Schema:
|
| 19 |
+
Each data point in the dataset consists of two elements:
|
| 20 |
+
* context: A string containing the text snippet with the embedded table.
|
| 21 |
+
* answer: A JSON object representing the extracted table structure.
|
| 22 |
+
The JSON object follows this format:
|
| 23 |
+
{
|
| 24 |
+
"column_1": { "row_id": "val1", "row_id": "val2", ... },
|
| 25 |
+
"column_2": { "row_id": "val1", "row_id": "val2", ... },
|
| 26 |
+
...
|
| 27 |
+
}
|
| 28 |
+
Each key in the JSON object represents a column header, and the corresponding value is another object containing key-value pairs for each row in that column.
|
| 29 |
+
|
| 30 |
+
## Examples:
|
| 31 |
+
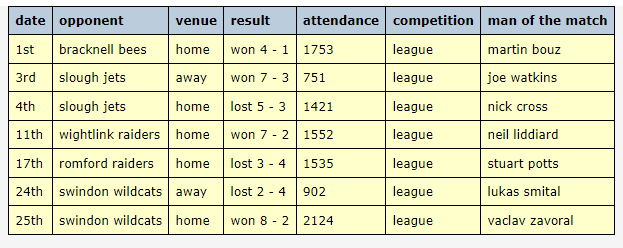
### Example 1:
|
| 32 |
+
#### Context:
|
| 33 |
+

|
| 34 |
+
#### Answer:
|
| 35 |
+
```json
|
| 36 |
+
{
|
| 37 |
+
"aircraft": {
|
| 38 |
+
"0": "robinson r - 22",
|
| 39 |
+
"1": "bell 206b3 jetranger",
|
| 40 |
+
"2": "ch - 47d chinook",
|
| 41 |
+
"3": "mil mi - 26",
|
| 42 |
+
"4": "ch - 53e super stallion"
|
| 43 |
+
},
|
| 44 |
+
"description": {
|
| 45 |
+
"0": "light utility helicopter",
|
| 46 |
+
"1": "turboshaft utility helicopter",
|
| 47 |
+
"2": "tandem rotor helicopter",
|
| 48 |
+
"3": "heavy - lift helicopter",
|
| 49 |
+
"4": "heavy - lift helicopter"
|
| 50 |
+
},
|
| 51 |
+
"max gross weight": {
|
| 52 |
+
"0": "1370 lb (635 kg)",
|
| 53 |
+
"1": "3200 lb (1451 kg)",
|
| 54 |
+
"2": "50000 lb (22680 kg)",
|
| 55 |
+
"3": "123500 lb (56000 kg)",
|
| 56 |
+
"4": "73500 lb (33300 kg)"
|
| 57 |
+
},
|
| 58 |
+
"total disk area": {
|
| 59 |
+
"0": "497 ft square (46.2 m square)",
|
| 60 |
+
"1": "872 ft square (81.1 m square)",
|
| 61 |
+
"2": "5655 ft square (526 m square)",
|
| 62 |
+
"3": "8495 ft square (789 m square)",
|
| 63 |
+
"4": "4900 ft square (460 m square)"
|
| 64 |
+
},
|
| 65 |
+
"max disk loading": {
|
| 66 |
+
"0": "2.6 lb / ft square (14 kg / m square)",
|
| 67 |
+
"1": "3.7 lb / ft square (18 kg / m square)",
|
| 68 |
+
"2": "8.8 lb / ft square (43 kg / m square)",
|
| 69 |
+
"3": "14.5 lb / ft square (71 kg / m square)",
|
| 70 |
+
"4": "15 lb / ft square (72 kg / m square)"
|
| 71 |
+
}
|
| 72 |
+
}
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
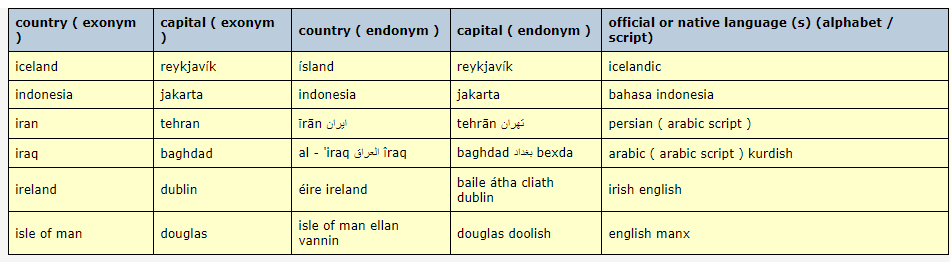
### Example 2:
|
| 76 |
+
#### Context:
|
| 77 |
+

|
| 78 |
+
#### Answer:
|
| 79 |
+
```json
|
| 80 |
+
{
|
| 81 |
+
"country": {
|
| 82 |
+
"exonym": {
|
| 83 |
+
"0": "iceland",
|
| 84 |
+
"1": "indonesia",
|
| 85 |
+
"2": "iran",
|
| 86 |
+
"3": "iraq",
|
| 87 |
+
"4": "ireland",
|
| 88 |
+
"5": "isle of man"
|
| 89 |
+
},
|
| 90 |
+
"endonym": {
|
| 91 |
+
"0": "ísland",
|
| 92 |
+
"1": "indonesia",
|
| 93 |
+
"2": "īrān ایران",
|
| 94 |
+
"3": "al - 'iraq العراق îraq",
|
| 95 |
+
"4": "éire ireland",
|
| 96 |
+
"5": "isle of man ellan vannin"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
"capital": {
|
| 100 |
+
"exonym": {
|
| 101 |
+
"0": "reykjavík",
|
| 102 |
+
"1": "jakarta",
|
| 103 |
+
"2": "tehran",
|
| 104 |
+
"3": "baghdad",
|
| 105 |
+
"4": "dublin",
|
| 106 |
+
"5": "douglas"
|
| 107 |
+
},
|
| 108 |
+
"endonym": {
|
| 109 |
+
"0": "reykjavík",
|
| 110 |
+
"1": "jakarta",
|
| 111 |
+
"2": "tehrān تهران",
|
| 112 |
+
"3": "baghdad بغداد bexda",
|
| 113 |
+
"4": "baile átha cliath dublin",
|
| 114 |
+
"5": "douglas doolish"
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"official or native language(s) (alphabet/script)": {
|
| 118 |
+
"0": "icelandic",
|
| 119 |
+
"1": "bahasa indonesia",
|
| 120 |
+
"2": "persian ( arabic script )",
|
| 121 |
+
"3": "arabic ( arabic script ) kurdish",
|
| 122 |
+
"4": "irish english",
|
| 123 |
+
"5": "english manx"
|
| 124 |
+
}
|
| 125 |
+
}
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
|
example1.png
ADDED
|
Git LFS Details
|
example2.png
ADDED
|
Git LFS Details
|
table_extract.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eccb38d12364c313b49a70750e7f246a2f9d91ef25779efb75beefc1ba4fd135
|
| 3 |
+
size 56920386
|